
- 버전
- 다운로드 12
- 파일 크기 855.54 KB
- 파일 수 1
- 생성 날짜 2022년 1월 6일
- 마지막 업데이트 2024년 2월 16일
[한국신용정보원 ] 부도 예측을 위한 인공지능 학습용 데이터 생성 및 검증 기법
한국신용정보원에서 발간한
부도 예측을 위한 인공지능 학습용 데이터 생성 및 검증기법입니다.
업무에 참고 바랍니다.
![]()
○ 자료명 : 부도 예측을 위한 인공지능 학습용 데이터 생성 및 검증 기법 : GAN(Generative Adversarial Network) 기반 재현 데이터 중심으로
○ 발간일 : 2022년 1월
0. 개요
인공지능 학습 모형 중 하나인 GAN() 모델을 적용해 부도 차주의 통계 특성은 최대한 유지하되 실제 자료는 아닌 재현된 학습 데이터를 생성하고 그 결과를 평가합니다.
- GAN 모델을 통한 재현데이터 생성 및 평가 결과, 신용정보를 포함하는 인공지능 학습 데이터로 재현 데이터를 활용할 수 있음을 시사합니다.
- 생성된 재현 학습 데이터는 실제 데이터셋의 분포 특성을 대체로 유지하고 있습니다. 실제 데이터셋과 유사하거나 개선된 분류 성능을 보이며 실제 데이터셋에서의 데이터 불균형 문제에 따른 낮은 재현율을 개선하는 효과를 보입니다.
- 향후 보다 효율적인 데이터 생성 기법 연구와 정교한 신뢰성 검증을 거쳐 금융산업 내 재현데이터 활용 확대를 기대하고 있습니다.
1. 부도 예측 학습 데이터 생성 및 검증 절차
- GAN((Generative Adversarial Network : 적대적 생성 신경말)은 딥러닝 생성 모델 중 하나로, 생성자(Generator)와 판별자(Discriminator)가 대립하는 구조로 실제에 가까움 샘플을 생성합니다.
- 생성자는 실제에 가까운 샘플을 생성하는 것으로 목표로 합니다. 판별자는 생성자가 만들어낸 샘플을 실제 데이터와 비교하여 실제와 가상 여부를 잘 구별해내는 것을 각각의 목표로 하고 있습니다.
- 1단계. 판별자는 실제 데이터와 생성자가 생성한 샘플을 학습하고 그 중 실제 데이터를 판별합니다.
- 2단계. 판별자가 학습을 통해 판별한 결과를 생성자가 학습해 더 실제에 가까운 샘플을 생성합니다.
- 3단계. 단계1~2를 반복하여 판별자가 실제 데이터와 생성한 샘플을 구분하지 못할 때 학습을 종료 합니다.
- 생성자는 실제에 가까운 샘플을 생성하는 것으로 목표로 합니다. 판별자는 생성자가 만들어낸 샘플을 실제 데이터와 비교하여 실제와 가상 여부를 잘 구별해내는 것을 각각의 목표로 하고 있습니다.
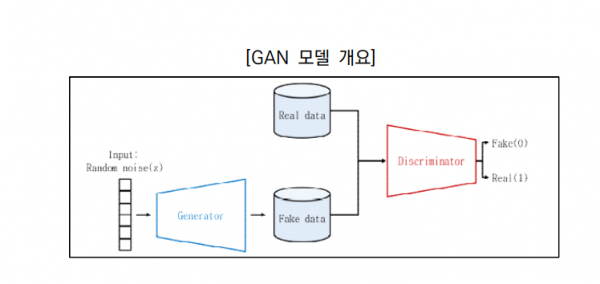
GAN 모델 개요
-
- 학습 데이터 생성 절차는 ①원천 데이터를 준비하고 ②재현 학습 데이터를 생성하고 ③생성된 데이터를 검증하고 평가하는 단계로 이뤄집니다.
2. 요약 및 시사점
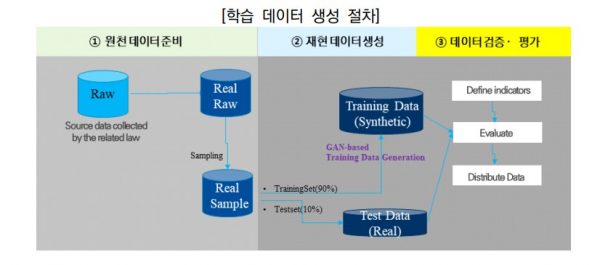
학습 데이터 생정 절차 개요
- 데이터 보유 기관의 경우에는 민감한 데이터를 포함하는 데이터를 공개에 한계가 있습니다. 빅데이터를 분석하는 기업 혹은 인공지능 기술을 개발하는 기업은 분석에 활용할 데이터를 구하기 어렵습니다.
- 실제 데이터의 특성을 최대한 유지한 가상의 데이터 생성과 활용을 통해 학습 데이터 확보 방안을 모색 중입니다.
- 최근 연구가 활발한 GAN 모델을 적용하여 부도 예측을 위한 학습 데이터를 생성, 실제 원천 데이터와 비교하면서 학습 데이터의 활용 가능성을 검토해야 합니다.
- 재현 데이터는 원천 자료를 그대로 제공하지 못하는 경우에 대안으로 활발히 연 되고 있습니다.
- GAN 모델을 통해 재현 데이터를 생성하고 실제 데이터와 비교 검증하여 실제 데이터와 유사하면서 데이터 불균형 문제를 해소한 새로운 학습데이터를 생성할 수 있는 가능성을 제시합니다.
- 부도 차주의 실제 분포 특성을 유지하는 재현 데이터를 포함한 학습 데이터를 이용 시, 실제 데이터 대비 유사 성능 혹은 개선될 수 있음을 보입니다.
더 자세한 내용은 한국신용정보원에서 발간한 자료를 참고 바랍니다.
함께 읽으면 좋은 글
